Deploy a Transformer model with BentoML#
This quickstart demonstrates how to build a text summarization application with a Transformer model (sshleifer/distilbart-cnn-12-6) from the Hugging Face Model Hub. It helps you become familiar with the core concepts of BentoML and gain a basic understanding of the model serving lifecycle in BentoML.
Specifically, you will do the following in this tutorial:
Set up the BentoML environment
Download a model
Create a BentoML Service
Build a Bento
Serve the Bento
(Optional) Containerize the Bento with Docker
Note
All the project files are stored on the quickstart GitHub repository.
Prerequisites#
Make sure you have Python 3.8+ and
pipinstalled. See the Python downloads page to learn more.(Optional) Install Docker if you want to containerize the Bento.
(Optional) We recommend you create a virtual environment for dependency isolation for this quickstart. For more information about virtual environments in Python, see Creation of virtual environments.
Install dependencies#
Run the following command to install the required dependencies, which include BentoML, Transformers, and Pytorch (or TensorFlow 2.0).
pip install bentoml transformers torch
Download a model to the local Model Store#
To create this text summarization AI application, you need to download the model first. This is done via a download_model.py script as below,
which uses the bentoml.transformers.save_model() function to import the model to the local Model Store. The BentoML Model Store is used for
managing all your local models as well as accessing them for serving.
import transformers
import bentoml
model= "sshleifer/distilbart-cnn-12-6"
task = "summarization"
bentoml.transformers.save_model(
task,
transformers.pipeline(task, model=model),
metadata=dict(model_name=model),
)
Starting from BentoML version 1.1.9, you can also use the bentoml.transformers.import_model function to import the model directly without having to load it into memory first,
which is particularly useful for large models. For example:
import bentoml
model = "sshleifer/distilbart-cnn-12-6"
task = "summarization"
# Import the model directly without loading it into memory
bentoml.transformers.import_model(
name=task,
model_name_or_path=model,
metadata=dict(model_name=model)
)
For more information about BentoML’s integration with the Transformers framework, see Transformers.
Create and run this script to download the model.
python download_model.py
Note
It is possible to use pre-trained models directly with BentoML or import existing trained model files to BentoML. See Models to learn more.
The model should appear in the Model Store with the name summarization if the download is successful. You can retrieve this model later to
create a BentoML Service. Run bentoml models list to view all available models in the Model Store.
$ bentoml models list
Tag Module Size Creation Time
summarization:5kiyqyq62w6pqnry bentoml.transformers 1.14 GiB 2023-07-10 11:57:40
Note
All models downloaded to the Model Store are saved in the directory /home/user/bentoml/models/. You can manage saved models via
the bentoml models CLI command or Python API. For more information, see Manage models.
Create a BentoML Service#
With a ready-to-use model, you define a BentoML Service by creating a service.py file as below. This is where the serving logic is defined.
import bentoml
summarizer_runner = bentoml.models.get("summarization:latest").to_runner()
svc = bentoml.Service(
name="summarization", runners=[summarizer_runner]
)
@svc.api(input=bentoml.io.Text(), output=bentoml.io.Text())
async def summarize(text: str) -> str:
generated = await summarizer_runner.async_run(text, max_length=3000)
return generated[0]["summary_text"]
This script creates a summarizer_runner instance from the previously downloaded model, retrieved through the bentoml.models.get() function.
A Runner in BentoML is a computational unit that encapsulates a machine learning model. It’s designed for remote execution and independent scaling.
For more information, see Runners.
bentoml.Service() wraps the Runner and creates a Service. A BentoML Service encapsulates various components including Runners and an API server.
It serves as the interface to the outside world, processing incoming requests and outgoing responses. A single Service can house multiple Runners,
enabling the construction of more complex machine learning applications. The diagram below provides a high-level representation of a BentoML Service:
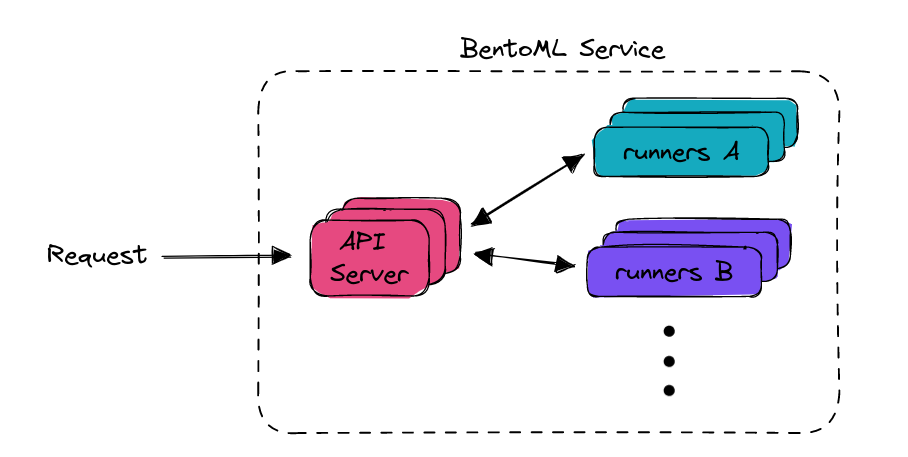
The summarize() function, decorated with @svc.api(), specifies the API endpoint for the Service and the logic to process the inputs and outputs.
For more information, see API IO Descriptors.
Run bentoml serve in your project directory to start the BentoML server.
$ bentoml serve service:svc
2023-07-10T12:13:33+0800 [INFO] [cli] Prometheus metrics for HTTP BentoServer from "service:svc" can be accessed at http://localhost:3000/metrics.
2023-07-10T12:13:34+0800 [INFO] [cli] Starting production HTTP BentoServer from "service:svc" listening on http://0.0.0.0:3000 (Press CTRL+C to quit)
The server is now active at http://0.0.0.0:3000. You can interact with it in different ways.
curl -X 'POST' \
'http://0.0.0.0:3000/summarize' \
-H 'accept: text/plain' \
-H 'Content-Type: text/plain' \
-d '$PROMPT' # Replace $PROMPT here with your prompt.
import requests
response = requests.post(
"http://0.0.0.0:3000/summarize",
headers={
"accept": "text/plain",
"Content-Type": "text/plain",
},
data="$PROMPT", # Replace $PROMPT here with your prompt.
)
print(response.text)
Visit http://0.0.0.0:3000, scroll down to Service APIs, and click Try it out. In the Request body box, enter your prompt and click Execute.
See the following example that summarizes the concept of large language models.
Input:
A large language model (LLM) is a computerized language model, embodied by an artificial neural network using an enormous amount of "parameters" (i.e. "neurons" in its layers with up to tens of millions to billions "weights" between them), that are (pre-)trained on many GPUs in relatively short time due to massive parallel processing of vast amounts of unlabeled texts containing up to trillions of tokens (i.e. parts of words) provided by corpora such as Wikipedia Corpus and Common Crawl, using self-supervised learning or semi-supervised learning, resulting in a tokenized vocabulary with a probability distribution. LLMs can be upgraded by using additional GPUs to (pre-)train the model with even more parameters on even vaster amounts of unlabeled texts.
Output by the text summarization model:
A large language model (LLM) is a computerized language model, embodied by an artificial neural network using an enormous amount of "parameters" in its layers with up to tens of millions to billions "weights" between them . LLMs can be upgraded by using additional GPUs to (pre-)train the model with even more parameters on even vaster amounts of unlabeled texts .
Build a Bento#
Once the model is functioning properly, you can package it into the standard distribution format in BentoML, also known as a “Bento”. It is a self-contained archive that contains all the source code, model files, and dependencies required to run the Service.
To build a Bento, you need a configuration YAML file (by convention, it’s bentofile.yaml). This file defines the build options, such as dependencies,
Docker image settings, and models.
The example file below lists only the basic information required to build a Bento for running on CPU.
service: 'service:svc'
include:
- '*.py'
python:
packages:
- torch
- transformers
models:
- summarization:latest
For running on GPU, we should in addition specify the CUDA version to be used in the image.
service: 'service:svc'
include:
- '*.py'
python:
packages:
- torch
- transformers
docker:
cuda_version: 12.1.1
models:
- summarization:latest
See Bento build options to learn more.
Run bentoml build in your project directory (which should contain download_model.py, service.py, and bentofile.yaml now) to build the Bento. You can find all created Bentos in /home/user/bentoml/bentos/.
$ bentoml build
Building BentoML service "summarization:ulnyfbq66gagsnry" from build context "/Users/demo/Documents/bentoml-demo".
Packing model "summarization:5kiyqyq62w6pqnry"
██████╗░███████╗███╗░░██╗████████╗░█████╗░███╗░░░███╗██╗░░░░░
██╔══██╗██╔════╝████╗░██║╚══██╔══╝██╔══██╗████╗░████║██║░░░░░
██████╦╝█████╗░░██╔██╗██║░░░██║░░░██║░░██║██╔████╔██║██║░░░░░
██╔══██╗██╔══╝░░██║╚████║░░░██║░░░██║░░██║██║╚██╔╝██║██║░░░░░
██████╦╝███████╗██║░╚███║░░░██║░░░╚█████╔╝██║░╚═╝░██║███████╗
╚═════╝░╚══════╝╚═╝░░╚══╝░░░╚═╝░░░░╚════╝░╚═╝░░░░░╚═╝╚══════╝
Successfully built Bento(tag="summarization:ulnyfbq66gagsnry").
Possible next steps:
* Containerize your Bento with `bentoml containerize`:
$ bentoml containerize summarization:ulnyfbq66gagsnry
* Push to BentoCloud with `bentoml push`:
$ bentoml push summarization:ulnyfbq66gagsnry
View all available Bentos:
$ bentoml list
Tag Size Creation Time
summarization:ulnyfbq66gagsnry 1.25 GiB 2023-07-10 15:28:51
Note
Bentos are the deployment unit in BentoML, one of the most important artifacts to keep track of in your model deployment workflow. BentoML provides CLI commands and APIs for managing Bentos. See Managing Bentos to learn more.
Serve and deploy the Bento#
Once the Bento is ready, you can use bentoml serve to serve it as an HTTP server in production. Note that if you have multiple versions of the same model, you can change the latest tag to the corresponding version.
$ bentoml serve summarization:latest
2023-07-10T15:36:58+0800 [INFO] [cli] Environ for worker 0: set CPU thread count to 12
2023-07-10T15:36:58+0800 [INFO] [cli] Prometheus metrics for HTTP BentoServer from "summarization:latest" can be accessed at http://localhost:3000/metrics.
2023-07-10T15:36:59+0800 [INFO] [cli] Starting production HTTP BentoServer from "summarization:latest" listening on http://0.0.0.0:3000 (Press CTRL+C to quit)
You can containerize the Bento with Docker. When creating the Bento, a Dockerfile is created automatically at /home/user/bentoml/bentos/<bento_name>/<tag>/env/docker/. To create a Docker image based on this example model, simply run:
bentoml containerize summarization:latest
Note
For Mac computers with Apple silicon, you can specify the --platform option to avoid potential compatibility issues with some Python libraries.
bentoml containerize --platform=linux/amd64 summarization:latest
The Docker image’s tag is the same as the Bento tag by default. View the created Docker image:
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
summarization ulnyfbq66gagsnry da287141ef3e 7 seconds ago 2.43GB
Run the Docker image locally:
docker run -it --rm -p 3000:3000 summarization:ulnyfbq66gagsnry serve
With the Docker image, you can run the model on Kubernetes and create a Kubernetes Service to expose it so that your users can interact with it.
If you prefer a serverless platform to build and operate AI applications, you can deploy Bentos to BentoCloud. It gives AI application developers a collaborative environment and a user-friendly toolkit to ship and iterate AI products. For more information, see Deploy Bentos.
Note
BentoML provides a GitHub Action to help you automate the process of building Bentos and deploying them to the cloud. For more information, see GitHub Actions.