Models#
A model refers to a machine learning artifact that encapsulates both the algorithms and learned parameters. Once trained, a model can be used to make predictions on new, unseen data. BentoML provides a local Model Store to save and manage models, which is a local file directory maintained by BentoML.
This document explains key operations about models in BentoML.
Save a trained model#
To serve a model using BentoML, you need to first save the model instance to the Model Store with the BentoML API. In most cases,
you can use the save_model method for this purpose. For example, you use the following call to save the trained model
in the Iris quickstart.
saved_model = bentoml.sklearn.save_model("iris_clf", clf)
Note
It is also possible to use pre-trained models directly with BentoML, without saving it to the Model Store first. See Custom Runner to learn more.
For any existing model saved on disk, load the model into a Python session and then import it into the BentoML Model Store. The specific method to use depends on the framework of your model. As a management best practice, always register your model into the Model Store once you finish training and validation. This makes sure all your finalized models can be managed in one place.
When using the save_model method, you can optionally attach custom labels, metadata, or custom objects to be saved alongside your model in the Model Store:
bentoml.pytorch.save_model(
"demo_mnist", # Model name in the local Model Store
trained_model, # Model instance being saved
labels={ # User-defined labels for managing models in BentoCloud
"owner": "nlp_team",
"stage": "dev",
},
metadata={ # User-defined additional metadata
"acc": acc,
"cv_stats": cv_stats,
"dataset_version": "20210820",
},
custom_objects={ # Save additional user-defined Python objects
"tokenizer": tokenizer_object,
}
)
labels: Custom key-value pairs for managing models and providing identifying attributes, such asowner=nlp_teamandstage=dev.metadata: Additional context or evaluation metrics for the model, such as dataset version, training parameters, and model scores.custom_objects: Additional Python objects such as a tokenizer instance and a preprocessor function. These objects are serialized with cloudpickle.
Retrieve a saved model#
To load the model instance back into memory, use the framework-specific load_model method. For example:
import bentoml
from sklearn.base import BaseEstimator
model: BaseEstimator = bentoml.sklearn.load_model("iris_clf:latest")
Note
The load_model method is used here only for testing and advanced customizations.
For general model serving use cases, use Runners for running model inference. See the
Use model Runners section below to learn more.
For retrieving model information and accessing the to_runner API, use the get method:
import bentoml
bento_model: bentoml.Model = bentoml.models.get("iris_clf:latest")
print(bento_model.tag)
print(bento_model.path)
print(bento_model.custom_objects)
print(bento_model.info.metadata)
print(bento_model.info.labels)
my_runner: bentoml.Runner = bento_model.to_runner()
bentoml.models.get returns a bentoml.Model instance, linking to a saved model entry in the BentoML Model Store. You can then use the instance to get model information like
tag, labels, and custom objects and create a Runner from the model.
Note
BentoML provides framework-specific get methods, such as benotml.pytorch.get. They function the same as bentoml.models.get but verify that
the model found matches the specified framework.
Manage models#
Saved models are stored in BentoML’s Model Store. You can view and manage all saved models via the bentoml models command:
$ bentoml models list
Tag Module Size Creation Time
iris_clf:2uo5fkgxj27exuqj bentoml.sklearn 5.81 KiB 2022-05-19 08:36:52
iris_clf:nb5vrfgwfgtjruqj bentoml.sklearn 5.80 KiB 2022-05-17 21:36:27
$ bentoml models get iris_clf:latest
name: iris_clf
version: 2uo5fkgxj27exuqj
module: bentoml.sklearn
labels: {}
options: {}
metadata: {}
context:
framework_name: sklearn
framework_versions:
scikit-learn: 1.1.0
bentoml_version: 1.0.0
python_version: 3.8.12
signatures:
predict:
batchable: false
api_version: v1
creation_time: '2022-05-19T08:36:52.456990+00:00'
$ bentoml models delete iris_clf:latest -y
INFO [cli] Model(tag="iris_clf:2uo5fkgxj27exuqj") deleted
Import and export models#
You can export a model in the BentoML Model Store as a standalone archive file and share it between teams or move it between different build stages. For example:
$ bentoml models export iris_clf:latest .
Model(tag="iris_clf:2uo5fkgxj27exuqj") exported to ./iris_clf-2uo5fkgxj27exuqj.bentomodel
$ bentoml models import ./iris_clf-2uo5fkgxj27exuqj.bentomodel
Model(tag="iris_clf:2uo5fkgxj27exuqj") imported
You can export models to and import models from external storage devices, such as AWS S3, GCS, FTP and Dropbox. For example:
pip install fs-s3fs # Additional dependency required for working with s3
bentoml models export iris_clf:latest s3://my_bucket/my_prefix/
Push and pull models#
BentoCloud provides a centralized model repository with flexible APIs
and a Web UI for managing all models (and Bentos) created by your team. After
you log in to BentoCloud, use bentoml models push and bentoml models pull to upload your models to
and download them from BentoCloud:
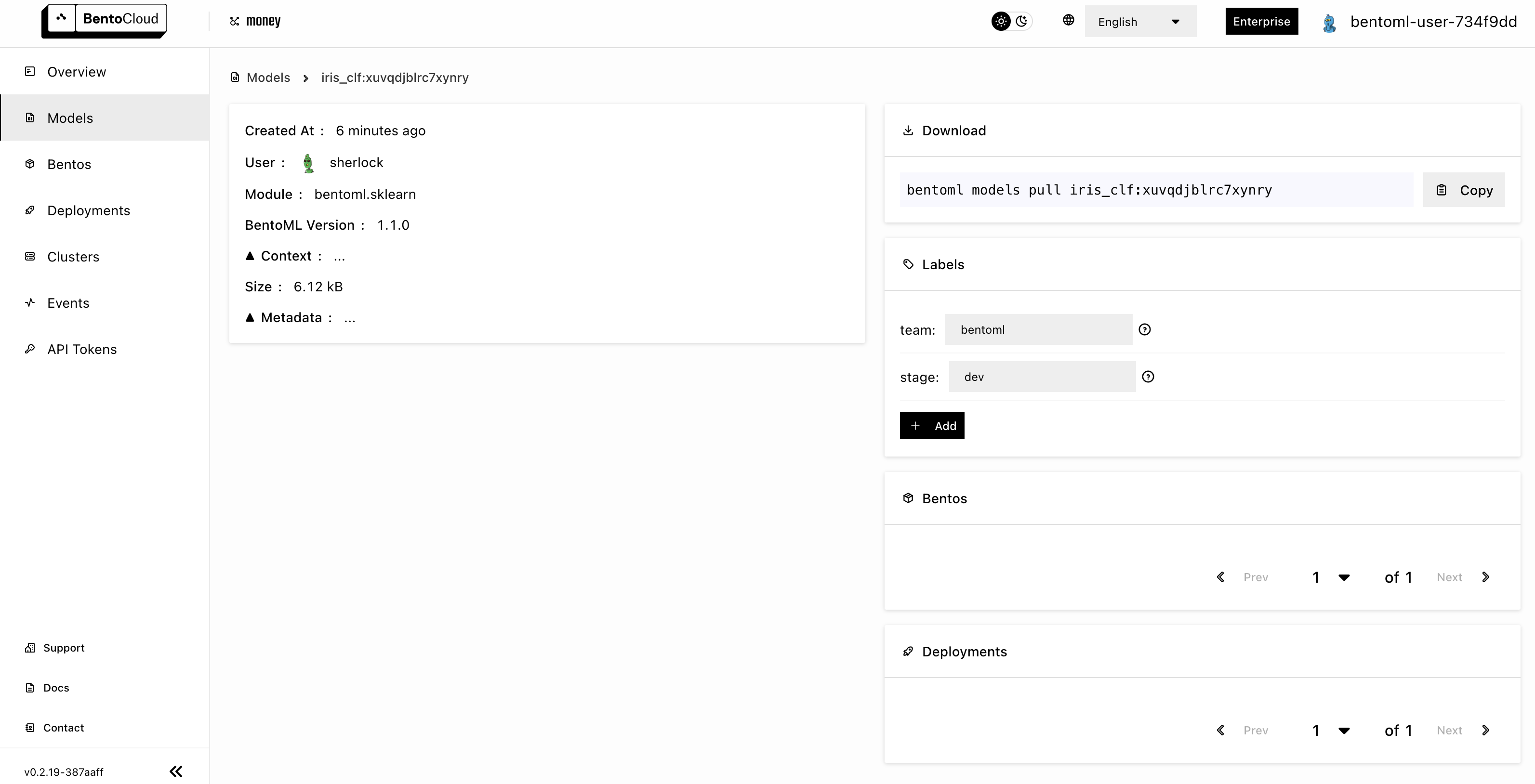
$ bentoml models push iris_clf:latest
Successfully pushed model "iris_clf:xuvqdjblrc7xynry" │
$ bentoml models pull iris_clf:latest
Successfully pulled model "iris_clf:xuvqdjblrc7xynry"
Tip
Learn more about CLI usage from bentoml models --help.
Model management APIs#
In addition to the CLI commands, BentoML also provides equivalent Python APIs for managing models:
import bentoml
bento_model: bentoml.Model = bentoml.models.get("iris_clf:latest")
print(bento_model.path)
print(bento_model.info.metadata)
print(bento_model.info.labels)
bentoml.models.list returns a list of bentoml.Model instances:
import bentoml
models = bentoml.models.list()
import bentoml
bentoml.models.export_model('iris_clf:latest', '/path/to/folder/my_model.bentomodel')
bentoml.models.import_model('/path/to/folder/my_model.bentomodel')
Note
You can export models to and import models from external storage devices, such as AWS S3, GCS, FTP and Dropbox. For example:
bentoml.models.import_model('s3://my_bucket/folder/my_model.bentomodel')
If you have access to BentoCloud, you can also push local models to or pull models from it.
import bentoml
bentoml.models.push("iris_clf:latest")
bentoml.models.pull("iris_clf:latest")
import bentoml
bentoml.models.delete("iris_clf:latest")
Use model Runners#
You use Runners to run model inference in BentoML Services. The Runner abstraction gives the BentoServer more flexibility in scheduling inference computations, dynamically batching inference calls, and utilizing available hardware resources.
To create a model Runner from a saved model, use the to_runner API:
iris_clf_runner = bentoml.sklearn.get("iris_clf:latest").to_runner()
The Runner instance can then be used for creating a bentoml.Service:
svc = bentoml.Service("iris_classifier", runners=[iris_clf_runner])
@svc.api(input=NumpyNdarray(), output=NumpyNdarray())
def classify(input_series: np.ndarray) -> np.ndarray:
result = iris_clf_runner.predict.run(input_series)
return result
To test out the Runner interface before defining the Service API callback function, you can create a local Runner instance outside of a Service:
# Create a Runner instance:
iris_clf_runner = bentoml.sklearn.get("iris_clf:latest").to_runner()
# Initialize the Runner in the current process (for development and testing only):
iris_clf_runner.init_local()
# This should yield the same result as the loaded model:
iris_clf_runner.predict.run([[5.9, 3, 5.1, 1.8]])
To learn more about Runner usage and its architecture, see Runners.
Model signatures#
A model signature represents a method on a model object that can be called. This information is used when creating BentoML Runners for this model.
For example, the iris_clf_runner.predict.run call in the previous section passes through
the function input to the model’s predict method, running from a remote Runner process.
For many other ML frameworks, the model object’s inference
method may not be called predict. You can customize it by specifying the model
signature when using save_model:
bentoml.pytorch.save_model(
"demo_mnist", # Model name in the local Model Store
trained_model, # Model instance being saved
signatures={ # Model signatures for Runner inference
"classify": {
"batchable": False,
}
}
)
runner = bentoml.pytorch.get("demo_mnist:latest").to_runner()
runner.init_local()
runner.classify.run( MODEL_INPUT )
A special case here is Python’s magic method __call__. Similar to the
Python language convention, the call to runner.run will be applied to
the model’s __call__ method:
bentoml.pytorch.save_model(
"demo_mnist", # Model name in the local Model Store
trained_model, # Model instance being saved
signatures={ # Model signatures for Runner inference
"__call__": {
"batchable": False,
},
}
)
runner = bentoml.pytorch.get("demo_mnist:latest").to_runner()
runner.init_local()
runner.run( MODEL_INPUT )
Batching#
For model inference calls that supports handling a batched input, it is recommended to
enable batching for the target model signature. By doing this, runner.run calls
made from multiple Service workers can be dynamically merged to a larger batch and run
as one inference call in the Runner worker. Here’s an example:
bentoml.pytorch.save_model(
"demo_mnist", # Model name in the local Model Store
trained_model, # Model instance being saved
signatures={ # Model signatures for Runner inference
"__call__": {
"batchable": True,
"batch_dim": 0,
},
}
)
runner = bentoml.pytorch.get("demo_mnist:latest").to_runner()
runner.init_local()
runner.run( MODEL_INPUT )
Note
The Runner interface remains consistent irrespective of the batchable parameter being set to True or False.
The batch_dim parameter determines the dimension(s) that contain multiple data
when passing to this run method. If it remains undefined, the default batch_dim value is 0.
For example, when running prediction on two dataset inputs, [1, 2] and
[3, 4], if the array passed to the predict method were [[1, 2], [3, 4]],
then the batch dimension would be 0. If you were to send [[1, 3], [2, 4]], then the batch dimension would be 1. The following code
snippet lists more examples.
# Save two models with `predict` method that supports taking input batches on the
# dimension 0 and the other on dimension 1:
bentoml.pytorch.save_model("demo0", model_0, signatures={
"predict": {"batchable": True, "batch_dim": 0}}
)
bentoml.pytorch.save_model("demo1", model_1, signatures={
"predict": {"batchable": True, "batch_dim": 1}}
)
# If the following calls are batched, the input to the actual predict method on the
# model.predict method would be [[1, 2], [3, 4], [5, 6]]
runner0 = bentoml.pytorch.get("demo0:latest").to_runner()
runner0.init_local()
runner0.predict.run(np.array([[1, 2], [3, 4]]))
runner0.predict.run(np.array([[5, 6]]))
# If the following calls are batched, the input to the actual predict method on the
# model.predict would be [[1, 2, 5], [3, 4, 6]]
runner1 = bentoml.pytorch.get("demo1:latest").to_runner()
runner1.init_local()
runner1.predict.run(np.array([[1, 2], [3, 4]]))
runner1.predict.run(np.array([[5], [6]]))
Expert API
If there are multiple arguments to the run method and there is only one batch
dimension supplied, all arguments will use that batch dimension.
The batch dimension can also be a tuple of (input batch dimension, output batch
dimension). For example, if the predict method has its input batched along
the first axis and its output batched along the zeroth axis, batch_dim can
be set to (1, 0).
For online serving workloads, adaptive batching is a critical component that contributes to the overall performance. If throughput and latency are important to you, learn more about other Runner options and batching configurations in Runners and Adaptive Batching.