Deploy Stable Diffusion XL with dynamic LoRA adapters#
Image creation has become a significant use case in AI applications, especially with the advent of state-of-the-art models like Stable Diffusion (SD) and DeepFloyd IF. Using the common BentoML workflow, you can easily define a BentoML Service and spin up a server. Alternatively, there is a tool in the BentoML ecosystem specifically designed for image creation tasks, also known as OneDiffusion.
OneDiffusion is an open-source platform capable of running any Stable Diffusion model in production with ease and speed. With OneDiffusion, you can quickly serve SD and SDXL models without manually creating the Service file. In addition, it supports dynamically loading LoRA weights, which means you can easily switch between different LoRA adapters optimized for various tasks without restarting the entire model.
This quickstart demonstrates how to use OneDiffusion to create an image generation application based on SDXL.
Note
You can try a similar project to this quickstart on Google Colab.
Prerequisites#
You have Python 3.8+ and
pipinstalled. See the Python downloads page to learn more.(Optional) Install Docker if you want to containerize the Bento.
(Optional) We recommend you create a virtual environment for dependency isolation for this quickstart. For more information about virtual environments in Python, see Creation of virtual environments.
Install OneDiffusion#
Run the following command to install OneDiffusion. It installs BentoML automatically if you have not installed it.
pip install onediffusion
Start a SDXL server#
OneDiffusion allows you to start a SDXL server without manually creating a BentoML Service.
onediffusion start stable-diffusion-xl
Note
When running the above command, OneDiffusion uses stabilityai/stable-diffusion-2 to start the server by default. To use a specific model version, add the --model-id option. For more information about supported models, see the OneDiffusion GitHub repository.
To start a SD server, run:
onediffusion start stable-diffusion
OneDiffusion downloads the model to the BentoML local Model Store if it has not been registered before. To view your models, run bentoml models list.
$ bentoml models list
Tag Module Size Creation Time
pt-sdxl-stabilityai--stable-diffusion-xl-base-1.0:f898a3e026e802f68796b95e9702464bac78d76f bentoml.diffusers 13.24 GiB 2023-09-06 09:46:25
After started, the SDXL server should be ready to handle requests at http://0.0.0.0:3000. You can interact with it in different ways.
curl -X 'POST' \
'http://0.0.0.0:3000/text2img' \
-H 'accept: image/jpeg' \
-H 'Content-Type: application/json' \
--output output.jpeg \
-d '{
"prompt": "the scene is a picturesque environment with beautiful flowers and trees. In the center, there is a small cat. The cat is shown with its chin being scratched. It is crouched down peacefully. The cat's eyes are filled with excitement and satisfaction as it uses its small paws to hold onto the food, emitting a content purring sound.",
"negative_prompt": null,
"height": 1024,
"width": 1024,
"num_inference_steps": 50,
"guidance_scale": 7.5,
"eta": 0,
"lora_weights": null
}'
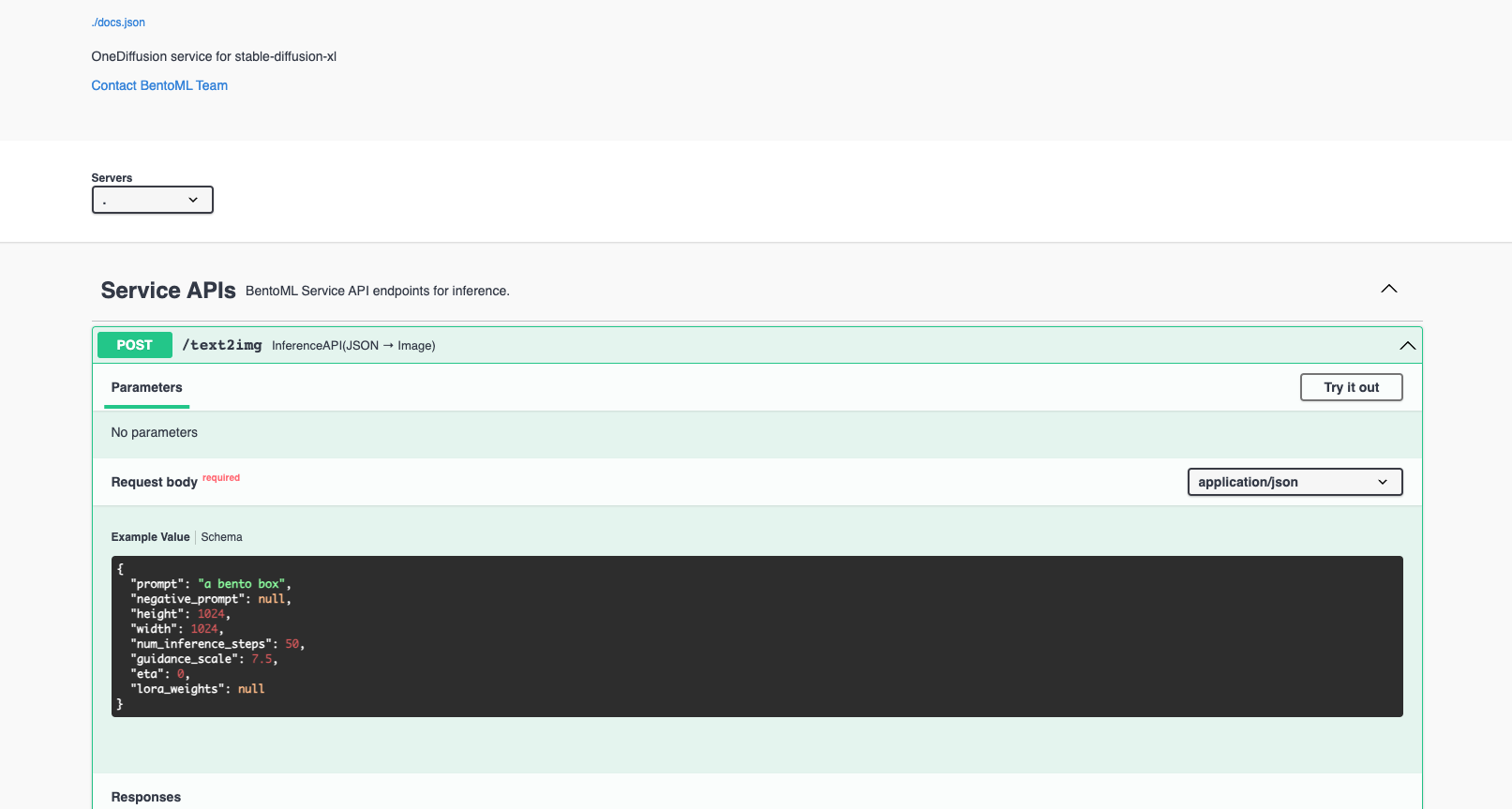
Visit http://0.0.0.0:3000, scroll down to Service APIs, select the /text2img endpoint, and click Try it out. In the Request body box, enter your prompt and click Execute.
An example image created:

Load LoRA adapters#
Dynamically loading LoRA adapters to SDXL means you can fine-tune the model to create task-specific images without the need to restart it.
To do so, simply specify the lora_weights field:
{
"prompt": "the scene is a picturesque environment with beautiful flowers and trees. In the center, there is a small cat. The cat is shown with its chin being scratched. It is crouched down peacefully. The cat's eyes are filled with excitement and satisfaction as it uses its small paws to hold onto the food, emitting a content purring sound.",
"negative_prompt": null,
"height": 1024,
"width": 1024,
"num_inference_steps": 50,
"guidance_scale": 7.5,
"eta": 0,
"lora_weights": "/path/to/lora-weights.safetensors"
}
You can send requests with the same prompt but different LoRA weights, creating images of varied styles. Example images created with different LoRA weights (oil painting vs pixel):

If you want to apply the LoRA weights when starting the SDXL server, add the --lora-weights option as below:
onediffusion start stable-diffusion-xl --lora-weights "/path/to/lora-weights.safetensors"
Build a Bento#
A Bento in BentoML is a deployable artifact with all the source code, models, data files, and dependency configurations. In BentoML, building a Bento usually requires you to create a bentofile.yaml file to include the metadata of your Bento. With OneDiffusion, however, you can use onediffusion build directly to build a Bento for SDXL.
$ onediffusion build stable-diffusion-xl
Packing 'stable-diffusion-xl' into a Bento with kwargs={}...
Building Bento for diffusion model 'stable-diffusion-xl'
Building Bento for diffusion model 'stable-diffusion-xl'
██████╗ ███╗ ██╗███████╗██████╗ ██╗███████╗███████╗██╗ ██╗███████╗██╗ ██████╗ ███╗ ██╗
██╔═══██╗████╗ ██║██╔════╝██╔══██╗██║██╔════╝██╔════╝██║ ██║██╔════╝██║██╔═══██╗████╗ ██║
██║ ██║██╔██╗ ██║█████╗ ██║ ██║██║█████╗ █████╗ ██║ ██║███████╗██║██║ ██║██╔██╗ ██║
██║ ██║██║╚██╗██║██╔══╝ ██║ ██║██║██╔══╝ ██╔══╝ ██║ ██║╚════██║██║██║ ██║██║╚██╗██║
╚██████╔╝██║ ╚████║███████╗██████╔╝██║██║ ██║ ╚██████╔╝███████║██║╚██████╔╝██║ ╚████║
╚═════╝ ╚═╝ ╚═══╝╚══════╝╚═════╝ ╚═╝╚═╝ ╚═╝ ╚═════╝ ╚══════╝╚═╝ ╚═════╝ ╚═╝ ╚═══╝
Successfully built Bento(tag="pt-stabilityai-stable-diffusion-xl-base-1-0-text2img:f898a3e026e802f68796b95e9702464bac78d76f").
Possible next steps:
* Push to BentoCloud with `bentoml push`:
$ bentoml push pt-stabilityai-stable-diffusion-xl-base-1-0-text2img:f898a3e026e802f68796b95e9702464bac78d76f
* Containerize your Bento with `bentoml containerize`:
$ bentoml containerize pt-stabilityai-stable-diffusion-xl-base-1-0-text2img:f898a3e026e802f68796b95e9702464bac78d76f
When building the Bento, you can specify the pipeline that the model will be using with --pipeline as follows. Currently, it supports text2image (default) and img2img.
onediffusion start stable-diffusion --pipeline "img2img"
To package LoRA weights into the Bento, use the --lora-dir option to specify the directory where LoRA files are stored. These files can be dynamically loaded to the model when deployed with Docker or BentoCloud to create images of different styles.
onediffusion build stable-diffusion-xl --lora-dir "/path/to/lorafiles/dir/"
If you only have a single LoRA file to use, run the following instead:
onediffusion build stable-diffusion-xl --lora-weights "/path/to/lorafile"
Deploy a Bento#
To containerize the Bento with Docker, run:
bentoml containerize pt-stabilityai-stable-diffusion-xl-base-1-0-text2img:f898a3e026e802f68796b95e9702464bac78d76f
Note
When using the onediffusion build command in the previous section, you can add the --containerize option to containerize the resulting Bento.
You can then deploy the image to any Docker-compatible environment like Kubernetes. Alternatively, push the Bento to BentoCloud for better management capabilities, like autoscaling. For more information, see Deploy Bentos.